

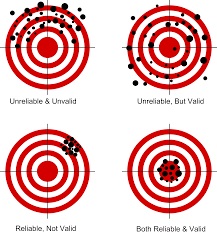
Collecting data is tricky. Data collection tools, like questionnaires, measure research study outcomes more or less well. A tool’s level of validity is how comprehensively & accurately the tool measures what it is supposed to measure (like stress, hope, etc); and reliabilityis how consistently it measures what it is supposed to measure. We’ve all had the experience of a weight-measuring bathroom scale breaking bad and changing our weight each time we step on it. That scale has validity, but no reliability. (See earlier post On Target all the time and everytime” )
Tools are more or less reliable & valid; none are perfect.

Validity is like hitting the right outcome target, and there are four (4) types of validity: 1) Face validity, 2) Content validity, 3) Construct validity, & 4) Criterion-related validity. Earlier posts focused on face & content validity as linked above. This blog focuses on #3: construct validity.
Construct validity is the level of tool accuracy & can be established by these statistical measures: a) convergent validity, b) discriminant/divergent validity, c) known groups, and d) factor analysis. For each of these, subjects (Ss) complete the measurement tool, & results are analyzed.

To illustrate, let’s assume we have a new pain data collection tool. In convergent validity, the same group of Ss complete the new pain tool and an already established pain tool (like self-report on 1-10 scale). Convergent construct validity exists when there is a positive correlation between the results from both tools. Scores on both tools should be similar for convergent validity.

For discriminant (or divergent) validity, all Ss complete the new pain tool and an established tool that measures the “opposite” or a dissimilar concept, such as feeling comfortable. Divergent validity of the new tool is revealed when there is no or low correlation between results from these 2 dissimilar tools. That’s a good thing! We should expect a big difference because the tools are measuring very different things. Pain & feeling comfortable should be very different in the same person at the same time for divergent validity.

Known groups validity means that we compare scores from subjects who exhibit & from those who do NOT exhibit what our tool is supposed to measure. For example, a group in pain and a group who are NOT in pain may fill out the new pain assessment tool. Scores of these two groups should obviously be very different on the new tool. Scores of the two groups should have an inverse,* no, or low correlation. If the two groups average scores are compared, the group means should be very different.* These differences between groups = known group construct validity. [*Notes: 1) “inverse” means that as one score goes up the other goes down; 2) t-test or ANOVA would be used to compare group means.]

Finally, a single group of subjects (Ss) may complete the instrument, and the researcher calculates statistical factor analysis. Factor analysis results arrange items into groups of similar items. The researcher examines each group of items (a factor) and labels it conceptually based on what s/he sees as their commonality. In our fictitious pain tool example, factor analysis may group items into three (3) main factors that the researcher labels as “physical aspects of pain,” “psychological aspects of pain,” and “disruption of relationships.”
FOR MORE INFO: Check out Highfield, M.E.F. (2025). Select Data Collection Tool. In: Doing Research: A practical guide for health professionals. Springer, Cham. https://doi.org/10.1007/978-3-031-79044-7_8
CRITICAL THINKING EXERCISE: Read this Google AI overview to test yourself on construct validity. Do you see any familiar ideas?
Pain scale construct validity is established when instruments (e.g., VAS, NRS, FPS-R) accurately measure the theoretical, multi-dimensional concept of pain—intensity, affect, and interference—rather than just a physical sensation. Evidence shows strong convergence between these tools (r=0.82–0.95), confirming they measure similar constructs.
Convergent Validity: High correlations exist between different, established pain scales (e.g., Numerical Rating Scale (NRS) and Visual Analogue Scale (VAS), indicating they measure the same construct.
Discriminant Validity: Pain scales show lower, non-significant correlations with unrelated variables (e.g., age, irrelevant behavioral factors), proving they specifically measure pain, not general distress.
Dimensionality: Construct validity in tools like the Brief Pain Inventory (BPI) is confirmed through factor analysis, which differentiates between pain intensity and pain interference.


















 Postal and electronic questionnaires are a relatively inexpensive way to collect information from people for research purposes. If people do not reply (so called ‘non-responders’), the research results will tend to be less accurate. This systematic review found several ways to increase response. People can be contacted before they are sent a postal questionnaire. Postal questionnaires can be sent by first class post or recorded delivery, and a stamped-return envelope can be provided. Questionnaires, letters and e-mails can be made more personal, and preferably kept short. Incentives can be offered, for example, a small amount of money with
Postal and electronic questionnaires are a relatively inexpensive way to collect information from people for research purposes. If people do not reply (so called ‘non-responders’), the research results will tend to be less accurate. This systematic review found several ways to increase response. People can be contacted before they are sent a postal questionnaire. Postal questionnaires can be sent by first class post or recorded delivery, and a stamped-return envelope can be provided. Questionnaires, letters and e-mails can be made more personal, and preferably kept short. Incentives can be offered, for example, a small amount of money with  a postal questionnaire. One or more reminders can be sent with a copy of the questionnaire to people who do not reply.
a postal questionnaire. One or more reminders can be sent with a copy of the questionnaire to people who do not reply.
 “What’s important is not where an organization begins its patient safety journey, but instead the degree to which it exhibits a relentless commitment to improvement.” – TJC, 2016, p.68
“What’s important is not where an organization begins its patient safety journey, but instead the degree to which it exhibits a relentless commitment to improvement.” – TJC, 2016, p.68