Patient Pain Satisfaction. It’s a key outcome of RN empathy in action.
Imagine that you are hospitalized and hurting. During hourly rounds the RN reassures you with these words: “We are going to do everything that we can to help keep your pain under control. Your pain management is our number 1 priority. Given your [condition, history, diagnosis, status], we may not be able to keep your pain level at zero. However, we will work very hard with you to keep you as comfortable as possible.” (Alaloul et al, 2015, p. 323).
Study? In 2015 a set of researchers tested effectiveness of the above pain script using 2 similar medical-surgical units in an academic medical center—1 unit was an experimental unit & 1 was a control unit. RNs rounded hourly on both units.  On the experimental unit RNs stated the script to patients exactly as written and on room whiteboards posted the script, last pain med & pain scores. Posters of the script were also posted on the unit. In contrast, on the control unit RN communication and use of whiteboard were dependent on individual preferences. Researchers measured effectiveness of the script by collecting HCAHPS scores 2 times before RNs began using the script (a baseline pretest) and then 5 times during and after RNs began using it (a posttest) on both units.
On the experimental unit RNs stated the script to patients exactly as written and on room whiteboards posted the script, last pain med & pain scores. Posters of the script were also posted on the unit. In contrast, on the control unit RN communication and use of whiteboard were dependent on individual preferences. Researchers measured effectiveness of the script by collecting HCAHPS scores 2 times before RNs began using the script (a baseline pretest) and then 5 times during and after RNs began using it (a posttest) on both units.
Results? On the experimental units significantly more patients reported that the team was doing everything they could to control pain and that the pain was well-controlled (p≤.05). And while experimental unit scores were trending up, control unit scores trended down. Other findings were that the RNs were satisfied with the script, and that RNs having a BSN or MSN had no effect.
Conclusions/Implications? “When nurses used clear and consistent communication with patients in pain, a positive effect was seen in patient satisfaction with pain management over time. This intervention was simple and effective. It could be replicated in a variety of health care organizations.” (p.321) [underline added]
Commentary: While an experiment would have created greater confidence that the script caused the improvements in patient satisfaction, an experiment would have been difficult or impossible. Researchers could not randomly assign patients to experimental & control units. Still, quasi-experimental research is relatively strong evidence, but it leaves the door open that something besides the script caused the improvements in HCAHPS scores.
 Critical thinking? What would prevent you from adopting or adapting this script in your own personal practice tomorrow? What are the barriers and facilitators to getting other RNs on your unit to adopt this script, including using whiteboards? Are there any risks to using the script? What are the risks to NOT using the script?
Critical thinking? What would prevent you from adopting or adapting this script in your own personal practice tomorrow? What are the barriers and facilitators to getting other RNs on your unit to adopt this script, including using whiteboards? Are there any risks to using the script? What are the risks to NOT using the script?
Want more info? See original reference – Alaloul, F., Williams, K., Myers, J., Jones, K.D., & Logsdon, M.C. (2015).Impact of a script-based communication intervention on patient satisfaction with pain management. Pain Management Nursing, 16(3), 321-327. http://dx.doi.org/10.1016/j.pmn.2014.08.008






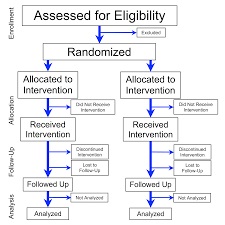
 In a quasi experimental design
In a quasi experimental design


 (Gray et al., 2006). About 12% of the 4 million born in U.S. hospitals were admitted to NICU’s. At birth every infant requires quick application of an armband, and when parents have not yet decided on a name the assigned name is often quite nondistinct (e.g., BabySmith).
(Gray et al., 2006). About 12% of the 4 million born in U.S. hospitals were admitted to NICU’s. At birth every infant requires quick application of an armband, and when parents have not yet decided on a name the assigned name is often quite nondistinct (e.g., BabySmith). Their results? RAR events were reduced by 36.3%. Their recommendations? Switch to a distinct naming system.
Their results? RAR events were reduced by 36.3%. Their recommendations? Switch to a distinct naming system.

