
 Quasi-experiments are a lot of work, yet don’t have the same scientific power to show cause and effect, as do randomized controlled trials (RCTs). An RCT would provide better support for any hypothesis that X causes Y. [As a quick review of what quasi-experimental versus RCT studies are, see “Of Mice & Cheese” and/or “Out of Control (Groups).”]
Quasi-experiments are a lot of work, yet don’t have the same scientific power to show cause and effect, as do randomized controlled trials (RCTs). An RCT would provide better support for any hypothesis that X causes Y. [As a quick review of what quasi-experimental versus RCT studies are, see “Of Mice & Cheese” and/or “Out of Control (Groups).”]
So why do quasi-experimental studies at all? Why not always do RCTs when we are testing cause and effect? Here are 3 reasons:
#1 Sometimes ETHICALLY the researcher canNOT randomly assign subjects to a control  and an experimental group. If the researcher wants to compare health outcomes of smokers with non-smokers, the researcher cannot assign some people to smoke and others not to smoke! Why? Because we already know that smoking has significant harmful effects. (Of course, in a dictatorship, by using the police a researcher could assign them to smoke or not smoke, but I don’t think we wanna go there.)
and an experimental group. If the researcher wants to compare health outcomes of smokers with non-smokers, the researcher cannot assign some people to smoke and others not to smoke! Why? Because we already know that smoking has significant harmful effects. (Of course, in a dictatorship, by using the police a researcher could assign them to smoke or not smoke, but I don’t think we wanna go there.)
#2 Sometimes PHYSICALLY the researcher canNOT randomly assign subjects to control &  experimental groups. If the researcher wants to compare health outcomes of
experimental groups. If the researcher wants to compare health outcomes of
individuals from different countries, it is physically impossible to assign country of origin.
#3 Sometimes FINANCIALLY the researcher canNOT afford to assign subjects randomly  to control & experimental groups. It costs $ & time to get a list of subjects and then assign them to control & experimental groups using random numbers table or drawing names from a hat.
to control & experimental groups. It costs $ & time to get a list of subjects and then assign them to control & experimental groups using random numbers table or drawing names from a hat.
Thus, researchers sometimes are left with little alternative, but to do a quasi-experiment as the next best thing to an RCT, then discuss its limitations in research reports.
Critical Thinking: You read a research study in which a researcher recruits the 1st 100 patients on a surgical ward January-March quarter as a control group. Then the researcher recruits the 2nd 100 patients on that same surgical ward April-June for the experimental group. With the experimental group, the staff uses a new, standardized pain script for better pain communications. Then the pain communication outcomes of each group are compared statistically.
- Is this a quasi-experiment or a randomized controlled trial (RCT)?
- What factors (variables) might be the same among control & experimental groups in this study?
- What factors (variables) might be different between control & experimental groups that might affect study outcomes?
- How could you design an ethical & possible RCT that would overcome the problems with this study?
- Why might you choose to do the study the same way that this researcher did?
For more info: see “Of Mice & Cheese” and/or “Out of Control (Groups).”

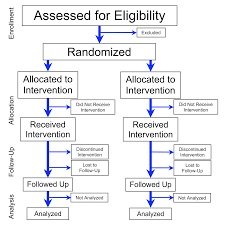
 In a quasi experimental design
In a quasi experimental design


 On the experimental unit RNs stated the script to patients exactly as written and on room whiteboards posted the script, last pain med & pain scores. Posters of the script were also posted on the unit. In contrast, on the control unit RN communication and use of whiteboard were dependent on individual preferences. Researchers measured effectiveness of the script by collecting HCAHPS scores 2 times before RNs began using the script (a baseline pretest) and then 5 times during and after RNs began using it (a posttest) on both units.
On the experimental unit RNs stated the script to patients exactly as written and on room whiteboards posted the script, last pain med & pain scores. Posters of the script were also posted on the unit. In contrast, on the control unit RN communication and use of whiteboard were dependent on individual preferences. Researchers measured effectiveness of the script by collecting HCAHPS scores 2 times before RNs began using the script (a baseline pretest) and then 5 times during and after RNs began using it (a posttest) on both units. Critical thinking? What would prevent you from adopting or adapting this script in your own personal practice tomorrow? What are the barriers and facilitators to getting other RNs on your unit to adopt this script, including using whiteboards? Are there any risks to using the script? What are the risks to NOT using the script?
Critical thinking? What would prevent you from adopting or adapting this script in your own personal practice tomorrow? What are the barriers and facilitators to getting other RNs on your unit to adopt this script, including using whiteboards? Are there any risks to using the script? What are the risks to NOT using the script?
 (Gray et al., 2006). About 12% of the 4 million born in U.S. hospitals were admitted to NICU’s. At birth every infant requires quick application of an armband, and when parents have not yet decided on a name the assigned name is often quite nondistinct (e.g., BabySmith).
(Gray et al., 2006). About 12% of the 4 million born in U.S. hospitals were admitted to NICU’s. At birth every infant requires quick application of an armband, and when parents have not yet decided on a name the assigned name is often quite nondistinct (e.g., BabySmith). Their results? RAR events were reduced by 36.3%. Their recommendations? Switch to a distinct naming system.
Their results? RAR events were reduced by 36.3%. Their recommendations? Switch to a distinct naming system.


